Материалы по тегу: ..
|
24.08.2022 [22:42], Владимир Мироненко
Untether AI представила ИИ-ускоритель speedAI240 — 1,5 тыс. ядер RISC-V и 238 Мбайт SRAM со скоростью 1 Пбайт/сКомпания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.  Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт. .jpg)
Изображения: Untether AI (via ServeTheHome) 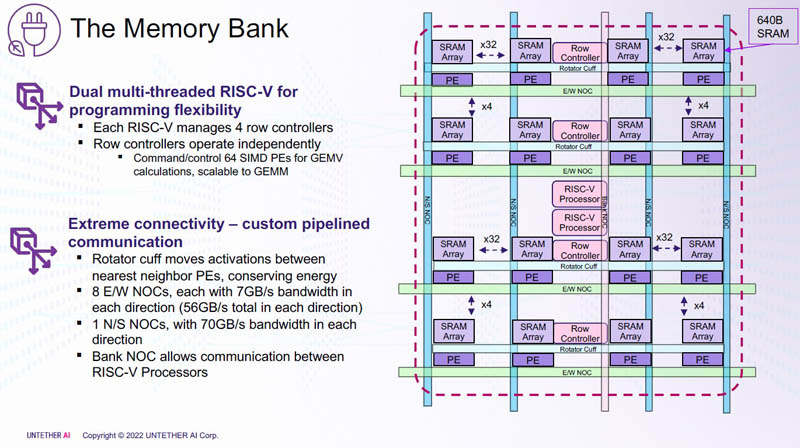 Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1. 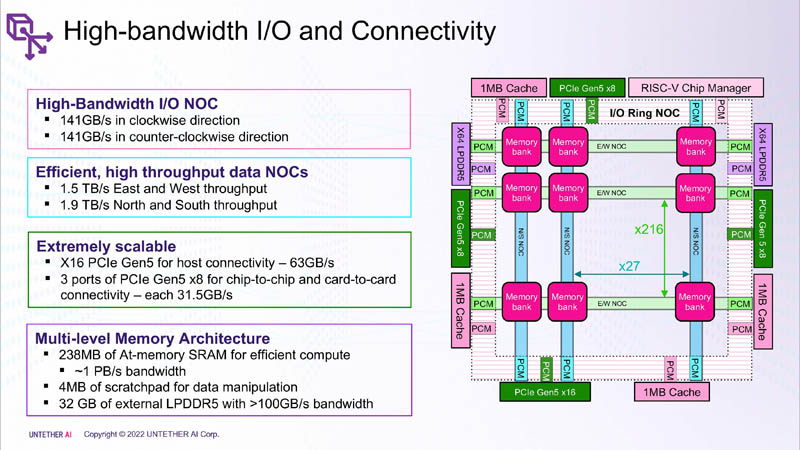 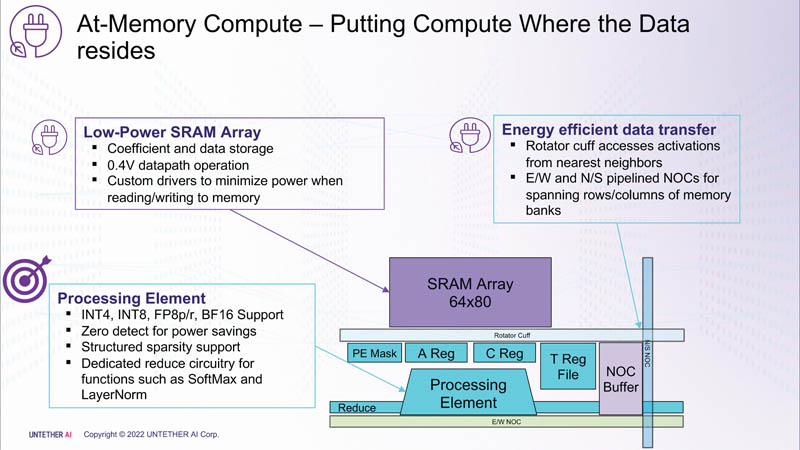 Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.  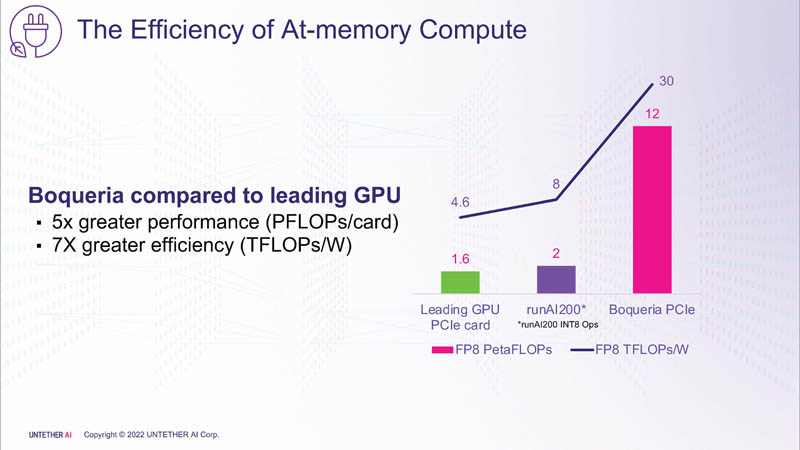 На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов. Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года.
03.03.2022 [19:00], Алексей Степин
Intel анонсировала новую версию платформы vPro, в том числе для ChromeOSВместе с расширением двенадцатого поколения процессоров Core (Alder Lake) компания Intel представила и новую версию бизнес-платформы vPro, обеспечивающую улучшенные возможности в области удалённого управления и информационной безопасности. Сама платформа vPro насчитывает уже более 15 лет, но сегодня некогда достаточно простой набор технологий разросся до полноценного портфолио, покрывающего потребности бизнес-клиентов в любых масштабах. 
Изображения: Intel Обновлённое портфолио включает следующие разновидности Intel vPro:
 В рамках новой версии vPro, по словам Intel, представлен полный спектр систем и решений, подходящий для любой задачи любой компании любого размера. Помимо всех тех особенностей, что предлагает архитектура Alder Lake (два вида ядер, DDR5 и т.д.), платформа vPro также включает ряд других программных и аппаратных компонентов:
 На момент анонса партнёрами Intel представлено более 150 различных дизайнов вычислительных платформ, во всех форм-факторах. Все они должны быть доступны уже в этом году. Не забыта и сфера IoT, где процессоры Intel двенадцатого поколения в сочетании с vPro обеспечат высокую производительность и удобство удалённого управления. Новинки этого типа отлично впишутся в современную розничную торговлю, образование медицину, производственные и банковские процессы, экосистемы «умных городов» и т.д.  С точки зрения Cisco, одного из крупнейших производителей сетевого оборудования, в новой платформе очень важна поддержка Wi-Fi 6E, не просто обеспечивающая настоящий «гигабит по воздуху», но и позволяющая без проблем подключать больше беспроводных устройств к точкам доступа, большую надёжность, и предсказуемость поведения Wi-Fi в сценариях класса mission critical. Компания считает очень удачным сочетание систем Intel с поддержкой Wi-Fi 6E c новыми точками доступа Cisco Catalyst и Meraki.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 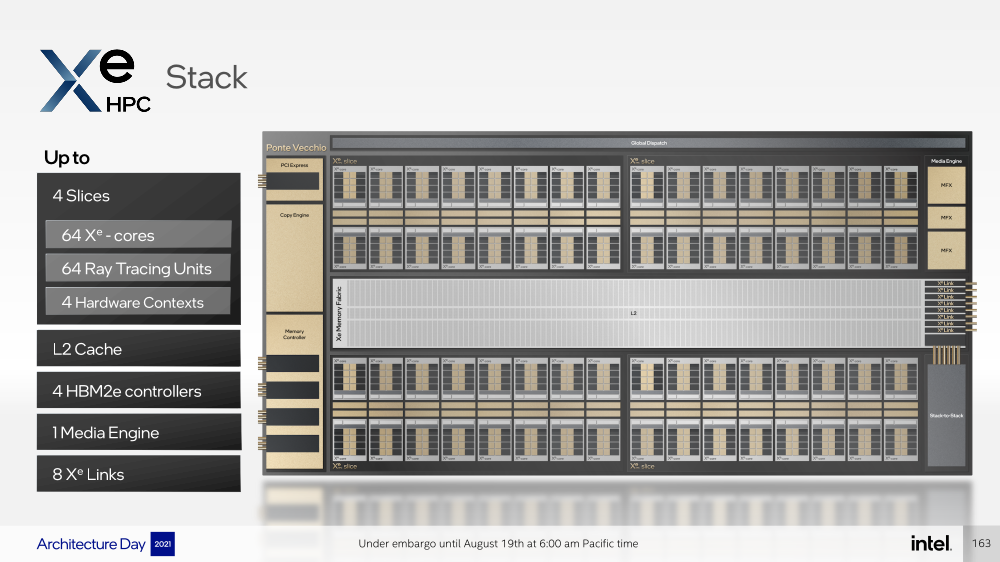 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 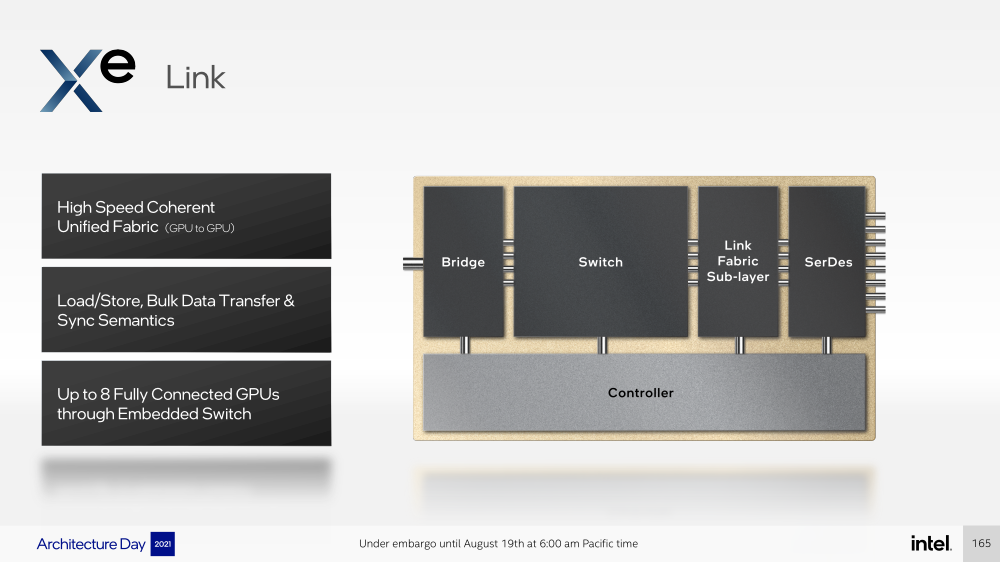  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 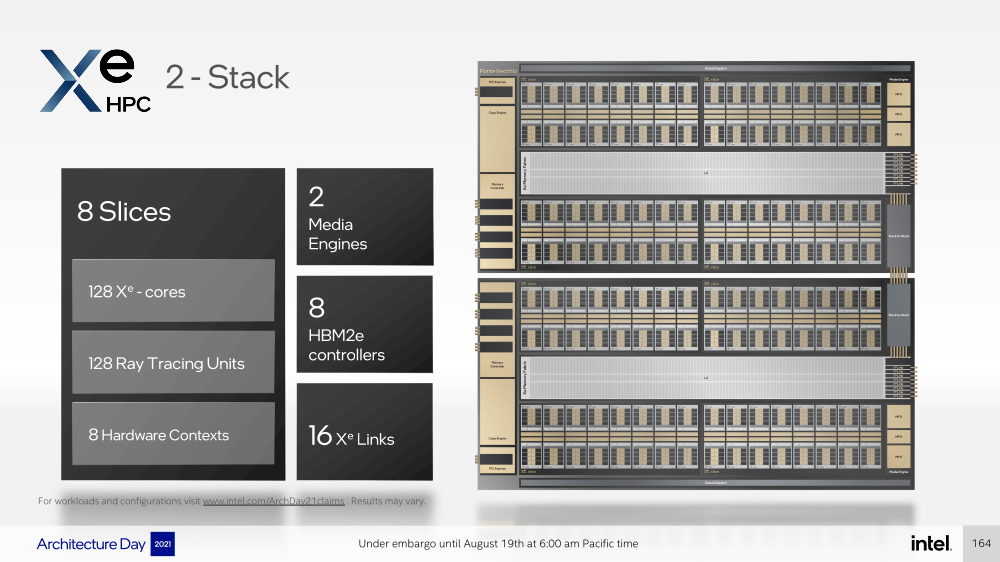 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA.
21.01.2021 [16:44], Сергей Карасёв
Плата Raspberry Pi Pico с микроконтроллером RP2040 оценена всего в $4Организация Raspberry Pi Foundation объявила о выпуске своего первого микроконтроллера: плата под названием Raspberry Pi Pico выполнена на основе микрочипа собственной разработки RP2040. В состав RP2040 входят два ядра Cortex M0+ с базовой тактовой частотой 48 МГц и возможностью повышения до 133 МГц. Предусмотрены 264 Кбайт памяти SRAM. Корпус: QFN56 с размерами 7 × 7 мм.  Собственно мини-плата Raspberry Pi Pico имеет габариты 51 × 21 мм. Она оснащена единственным разъёмом Micro-USB 1.1, который служит как для подачи питания, так и для загрузки прошивок в формате UF2. Имеется массив из 30 GPIO-контактов, позволяющий задействовать интерфейсы 2 × UART, 2 × I2C, 2 × SPI (всего до 16 Мбайт QSPI Flash с XIP), а также 16 PWM-каналов. Кроме того, упомянут температурный датчик и 4 ADC-канала. 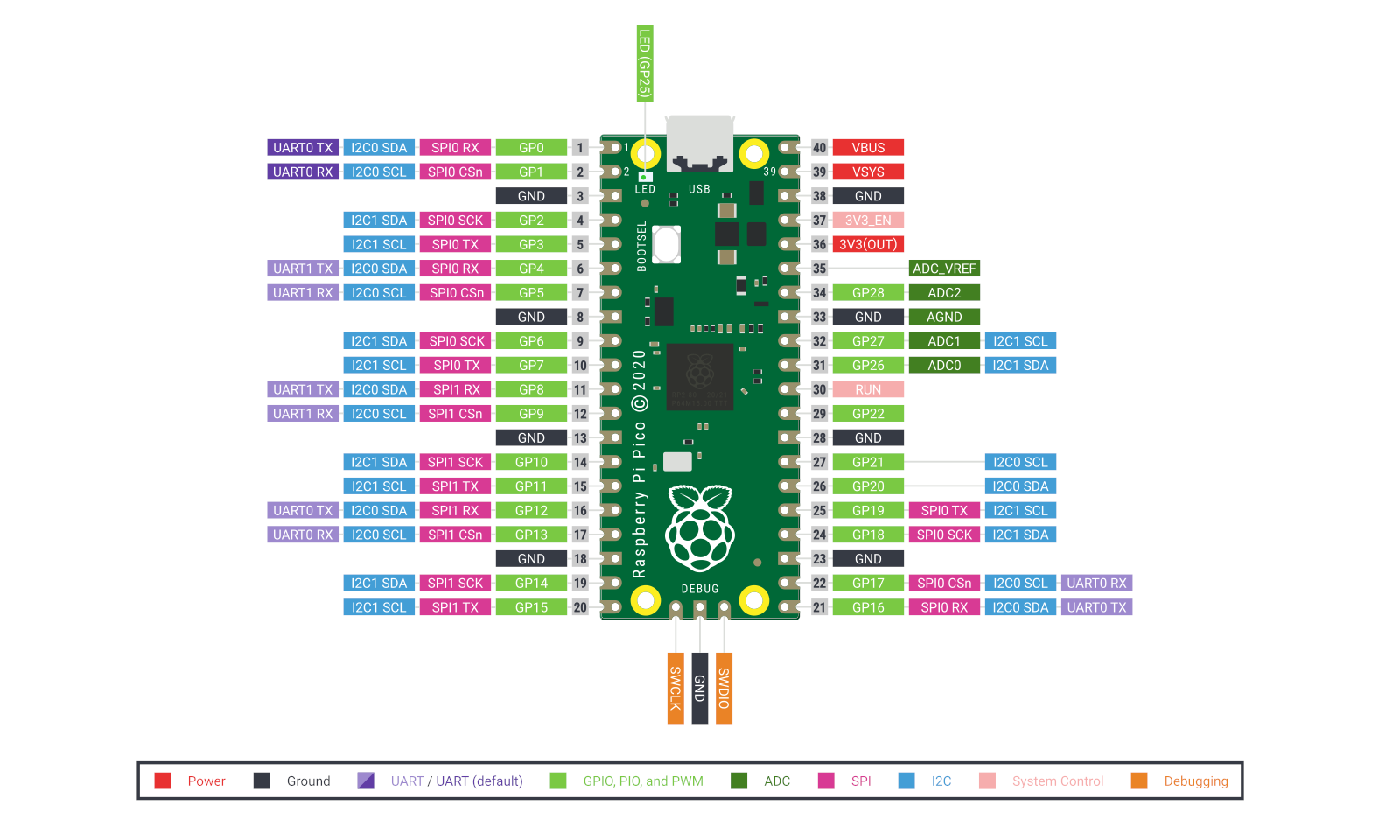 Микроконтроллер Raspberry Pi Pico может применяться в учебных целях, а также для создания тех или иных устройств для Интернета вещей, промышленной сферы и пр. Для упрощения работы имеются средства разработки на MicroPython и C/C++. Цена Raspberry Pi Pico с 2 Мбайт QSPI Flash составляет всего 4 доллара США.  Любопытно, что чип RP2040 также использоуетсяя в изделиях сторонних производителей. Свои решения на этой платформе уже представили Arduino, Adafruit, Sparkfun и Pimoroni. Они могут применяться для сбора различных данных, задач машинного обучения и пр. |
|

